Oh, no! We were several hours into a major system outage and there was still no clue as to what was broken. The webservers were running at full load and the applications were pumping a constant stream of error logs to disk. Systems and application engineers were frantically looking through the dizzying logs for clues as to the cause. Of course, looking at the logs, you would assume everything was broken, and it was. But even when the application worked, the logs were full of indecipherable errors. Everyone knew that most of the “errors” in the logs weren’t really errors, but untidy notices that developers had created long ago as part of a debugging exercise. As one engineer observed in some degree of frustration, “It’s like the log file that cried wolf!” After a while, nobody notices the errors.
The teams restarted services, rebooted systems, stopped and restarted load balancers. Nothing helped. Network engineers dug into the configuration of the routers and switches to make sure nothing was amiss. Except for the occasional keyboard typing sounds, dogs barking or children crying in the background, the intense investigation had produced an uncanny silence on the call. Operation center specialists were quickly crafting their communication updates and were discussing with the incident commander on how to update their many clients that were impacted by this outage. Company leaders and members of the board of directors were calling in to get updates. Stress was high. Would we ever find the cause or should we just shut down the company now and start over? Fatigue was setting in. Tempers were starting to show. Discussion ensued on the conference call to explore all mitigation options and next steps.
“I found it!” The discussion on the call stopped. Everyone perked up, anxious to hear the discovery. “What did you find?” the commander asked in a hopeful way. The giddy engineer took center stage on the call, eager to tell the news. “It’s the inventory service! The server at the fulfillment center seems to be intermittently timing out. Transactions are getting stuck in the queue.” The engineer paused, clearly typing away at some commands on his computer. “I think we have a routing problem. I try to trace it but it seems to bounce around and disappear. Sometimes it works, but to complete the transaction, multiple calls are required and too many of them are failing. I’m chatting with the fulfillment center and they report the inventory system is running.”
The engineer sent the traceroute to the network engineer who started investigating and then asked, “Can you send me the list of all the addresses used by the inventory system?” After some back and forth, the conclusion came, “I found the problem! There are two paths to the fulfillment center, one of which goes through another datacenter. That datacenter link looks up but it is clearly not passing traffic.” After more typing, the conclusion, “Ah, it seems the telco made a routing change. I’m getting them to reverse it now.” Soon the change was reversed and transactions were flowing again. The dashboards cleared and “green” lights came back on. Everyone on the bridge quietly, and sometimes not so silently, celebrated and felt an incredible emotional relief. Sure, there would be more questions, incident review and learning, but solving the problem was exhilarating.
How many of you can relate to a story like that? How many of you have been on that call?
A friend of mine, Dr. Steven Spear at MIT, often reminds us that the key to solving a problem is seeing the problem. You can’t solve what you cannot see. A big part of reliability engineering and systems dynamics is understanding how we gain visibility into problems and surface them so they can be addressed. Ideally, we find those weaknesses before they cause real business impact. That is often the attraction of chaos engineering, poking at fault domains to expose fractures that could become outages. But sometimes the issue is so complex that we just need a clear line of sight into the problem. In the story above, connectivity and those dependent links were not clearly visible. If there was some way to measure the foundational connectivity between the dependent locations, our operational heroes could have quickly seen it, fixed it, and gone back to sleep. Getting that visibility in advanced is the right thing to do for our business, our customers and our teams.
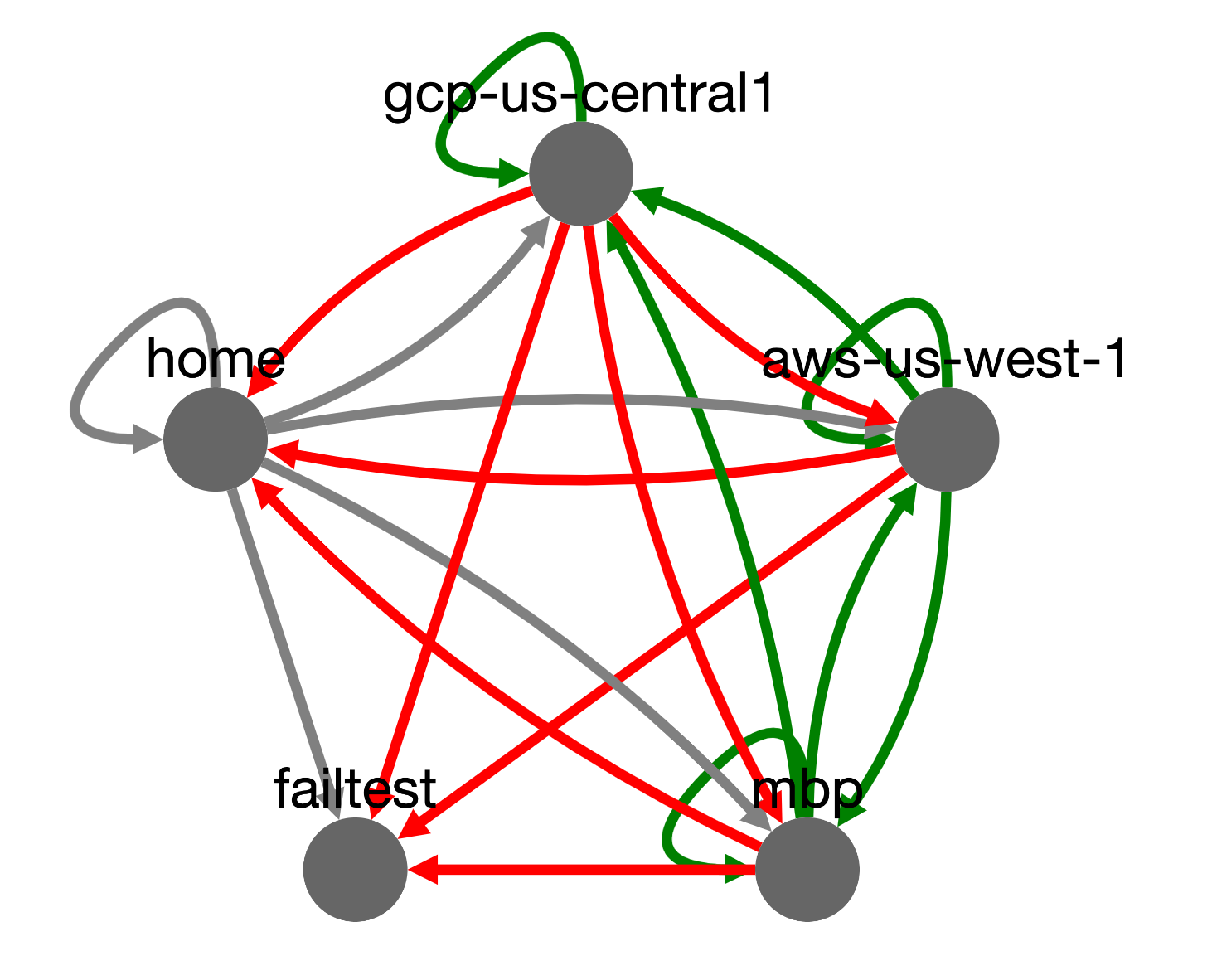
This past weekend, I found myself itching to code and tinker around with some new tech. The story above is one I have seen repeated multiple times. We often have limited visibility into point-to-point connectivity across our networks and vendors. Yet we have this grid of dependency that is needed to deliver our business powering technology. I know what you are thinking. There are millions of tools that do that. I found some and they were very elaborate and complicated, way more than what I wanted to experiment with. I finally had my excuse to code. I wanted to build a system to synthetically monitor all these links. Think of an instance in one datacenter or cloud polling an instance in another datacenter or region. I had a few hours this weekend so I blasted out some code. I created a tiny multithreaded python webservice that polls a list of other nodes and builds a graph database it displays using the JavaScript visualization library, cytoscape ,which was fun learning by itself. Of course, I packed this all into a container and gave it the catchy name, “GridBug”. Yes, I know, I’m a nerd.
You can throw a GridBug onto any instance, into any datacenter, and it will go to work monitoring connectivity. I didn’t have time to test any serverless options but it should work as well. I set up 5 nodes in 3 locations for a test, with some forced failures to see how it would detect conditions on the grid. The graph data converges overtime so that every node can render the same graph. If you want to see it, here is my test and project code: https://github.com/jasonacox/gridbug
I have no expectations on this project. It is clearly just a work of fun I wanted to share with all of you, but it occurs to me that there is still a lesson here. Pain or necessity is a mighty force in terms of inspiration. What bugs you? Like this outage example, is there some pain point that you would love to see addressed? What’s keeping you from trying to fix it? Come up with a project and go to work on it. You are going to learn something! Look, let’s be real, my project here is elementary and buggy at best (sorry, couldn’t resist the pun), but I got a chance to learn something new and see a fun result. That’s what makes projects like this so rewarding. The journey is the point, and frankly, you might even end up with something that brings some value to the rest of our human family. Go create something new this week!
Have a great week!